.jpg?table=block&id=30052c4c-a1ae-81ae-95ea-e12360a0bbc8&t=30052c4c-a1ae-81ae-95ea-e12360a0bbc8)
type
Post
status
Published
date
Feb 12, 2021 10:28
slug
summary
完整实战指南:从 MySQL binlog 配置到 Maxwell 实时采集 JSON、Kafka 消息队列传输、最终通过 Bireme 落地 Greenplum/HashData 的端到端数据同步方案。深度解析 bootstrap 全量初始化、分区倾斜优化、acks 可靠性配置、JavaScript 过滤器、多实例部署等核心技术点,附带 MissingTableMap、权限缺失、时区偏差等常见异常的排查思路与解决方案。
tags
ETL
Data Warehouse
Big Data
Maxwell
Kafka
category
Data Engineering
icon
password
wordCount
2037
前言
这篇笔记围绕 Maxwell + Kafka + Bireme 的数据同步链路,整理了从 MySQL 开启 binlog、Maxwell 增量/全量(bootstrap)、到 Bireme 落地 Greenplum/HashData 的常用配置、排错点与实践经验。
适用场景:你希望把 MySQL 变更实时写入 Kafka,再由下游(如 Bireme)消费写入数仓;同时需要了解全量初始化、分区倾斜、offset 跳过、DDL 兼容性等问题。
1. MySQL(MariaDB)开启 binlog
1.1 检查当前是否开启
若
log_bin = OFF 表示未开启,ON 表示已开启。1.2 修改配置并开启
MySQL 常见路径:
/etc/my.cnf MariaDB 常见路径:
/etc/my.cnf.d/server.cnf在
[mysqld] 中添加或修改:重启:
1.3 再次确认
server_id 在复制体系内必须唯一,并且 不能与 Canal 的 slaveId 冲突。2. Maxwell:把 binlog 变更输出为 JSON
Maxwell 会伪装为 MySQL Slave 读取 binlog events,并结合 schema 拼装为 JSON 输出,可直接投递到 Kafka。
2.1 创建用户与初始化表
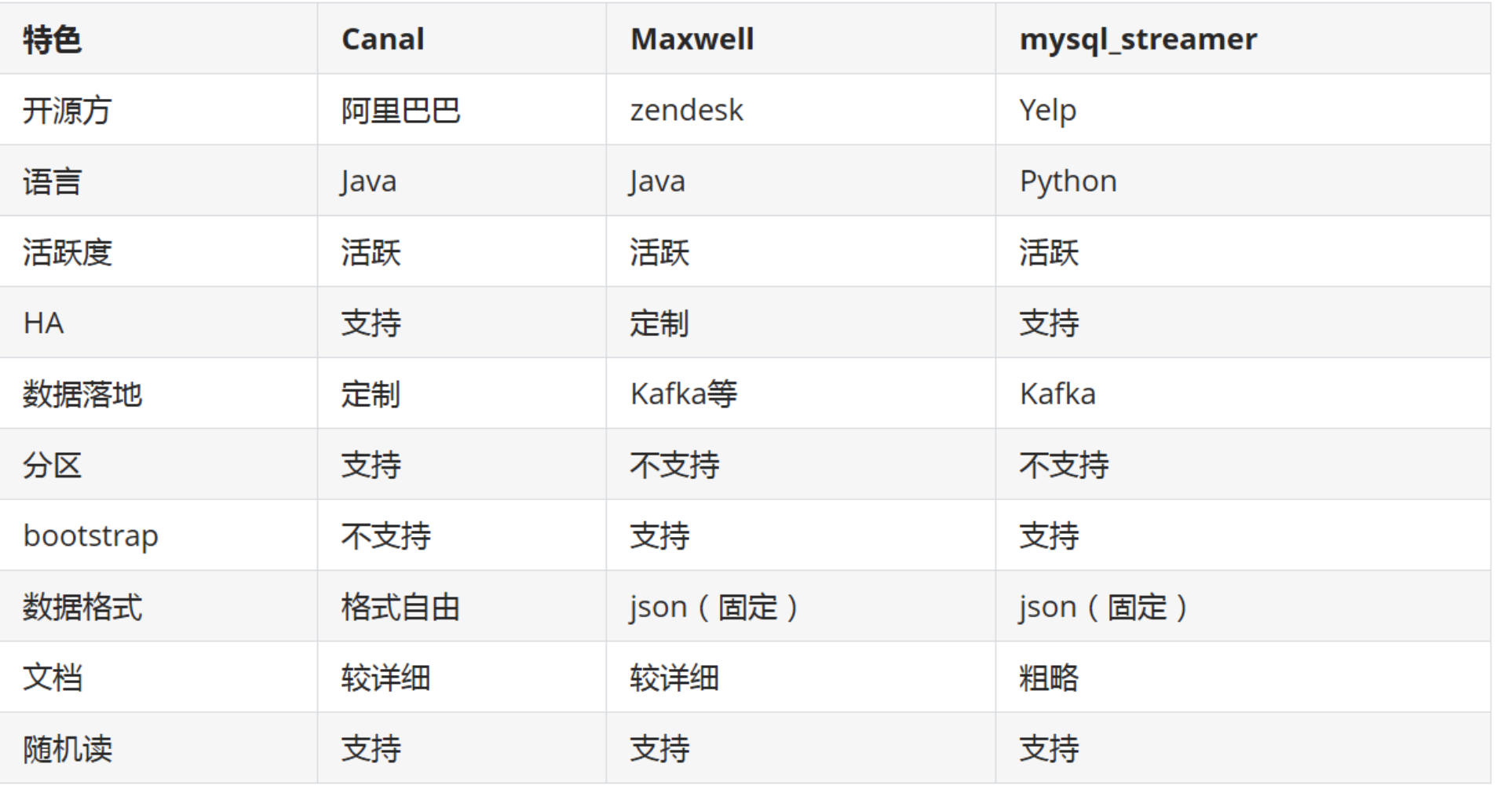
2.2 常见工具对比(Canal vs Maxwell)
Maxwell:配置简单,直接输出 JSON,不需要编写客户端解析协议。
Canal:生态更成熟,性能稳定,功能强大,但通常需要自研客户端消费解析结果。
(原图保留)
2.3 快速开始(stdout)
示例输出(JSON):
2.4 输出到 Kafka
创建 Topic:
启动消费者:
启动 Maxwell:
原文中
--host='localshot' 可能为拼写错误,应为 localhost。3. JSON 字段含义速查
字段 | 含义 |
data | 最新数据(变更后的行) |
old | 旧数据(变更前的字段子集) |
type | insert / update / delete / table-create / table-alter / bootstrap-insert 等 |
xid | 事务 ID |
commit | 同一 xid 的最后一条事件标记为 commit=true,便于事务重放 |
4. Maxwell 配置项(重点)
4.1 MySQL 角色拆分(理解 host / replication_host / schema_host)
Maxwell 会把 MySQL 连接用途分成三类:
- host:存储 Maxwell 元数据(schema、positions、heartbeats 等表)
- replication_host:实际读取 binlog 的主机
- schema_host:捕获 schema 的主机(binlog 里没有字段信息时使用)
大多数情况下三者是同一个 MySQL。只有在 binlog-proxy 等特殊场景,schema_host 才更常见。
4.2 Producer 关键配置(Kafka)
常用项包括:
producer:stdout / kafka / kinesis 等
kafka.bootstrap.servers
kafka_topic
kafka_partition_hash:default或murmur3
producer_partition_by:database/table/primary_key
5. 过滤器与 JavaScript 过滤
5.1 内置 filter(include / exclude / blacklist)
5.2 JavaScript 过滤器(增强灵活性)
当内置过滤器不够用,可以通过--javascript FILE编写脚本对行/DDL/心跳做二次处理。
(保留原示例代码,便于直接复用)
6. 数据初始化(bootstrap)
Maxwell 默认从上一次maxwell.positions的断点续读。如果 binlog 被 purge,需要 全量初始化,可用maxwell-bootstrap。
6.1 maxwell-bootstrap 命令
或手动往
maxwell.bootstrap 插入记录触发:6.2 bootstrap 事件序列
bootstrap-start
bootstrap-insert
bootstrap-complete
bootstrap 过程中 Maxwell 崩溃后重启,会 从头重新开始。若不希望重跑,可手动将
is_complete 置为 1,或删除该行记录。7. 监控与多实例
7.1 HTTP metrics
7.2 多实例(client_id)
同一主机运行多个 Maxwell 实例时,每个实例必须有唯一
client_id,否则 position 会互相覆盖。8. Kafka 分区倾斜与优化
当业务只有一个 database 时,默认
producer_partition_by=database 可能导致所有消息落到同一分区。推荐配置
如果主键分布不均,也可能倾斜。更稳妥的方式是结合业务 key 或某些列做
producer_partition_by=column,并评估 key 的基数与热度。9. 高可用(思路)
通过 ZooKeeper 做抢占式主备:启动时注册临时节点,监听节点消失后触发接管/重启。
参考:
10. 常见坑与排错清单
10.1 从旧 binlog 开始读取导致解析异常
若从一个事务中间位置开始读,可能缺失
TABLE_MAP,出现:MissingTableMapEventException排查方法:用
SHOW BINLOG EVENTS ... 确认指定 position 前是否已经出现 Table_map。10.2 权限不足导致“找不到表”
现象:
Couldn’t find table ... in database Maxwell ;原因是 Maxwell 构建元数据时没权限看到该表。解决:
- 给 Maxwell 用户补齐读权限并重建元数据
- 或用
--filter排除无权限表
10.3 timestamp 时区
Maxwell 对时间类型按字符串处理;
timestamp 本身带时区含义,binlog 解析通常输出 UTC。查看 MySQL 时区:
设置时区(示例 +8):
10.4 Kafka acks 与数据丢失
当
kafka.acks=1 时,极端情况下 Leader 写盘后返回成功但未复制到 ISR,Leader 宕机会丢消息。建议:
acks | 含义 |
0 | 不等待确认,最快但最不可靠 |
1 | Leader 写入本地日志即确认,可能丢消息 |
all | 等待 ISR 同步确认,可靠性最高 |
11. Bireme(增量)
Bireme 是面向 Greenplum/HashData 的增量同步工具,典型方式是 DELETE + COPY。
(保留原文的工作原理与配置示例,便于按环境直接落地)
12. mysql2pgsql(全量)
当 Bireme 不支持解析某些 bootstrap JSON 时,可考虑使用 mysql2pgsql 做一次性全量同步。
(保留原文的下载、配置与常见异常,便于直接执行)
参考文章 / 官方资料
- mysql2pgsql(RDS DBSync)
结尾(总结)
本文把 MySQL → Maxwell → Kafka → Bireme → Greenplum/HashData 这条数据链路按“能跑起来、跑得稳、出问题能定位”的顺序串起来:
- 上游(MySQL):先把 binlog 配好(ROW、唯一 server_id、必要权限),这是后续所有增量同步的根。
- 采集(Maxwell):明确 stdout/kafka 两种输出方式,理解
data/old/type/xid/commit的含义,掌握 host/replication_host/schema_host 的职责拆分。
- 稳定性(Kafka):分区策略决定吞吐和倾斜风险,
acks与 offset 策略决定可靠性与可回放能力。
- 全量与兼容性:bootstrap 用于补全“第一次全量”或 binlog 被清理后的恢复,但要注意下游(如 Bireme)对 DDL、bootstrap 事件的解析限制。
- 排错方法:遇到 MissingTableMap、权限不足找不到表、时区偏差、以及极端丢消息等问题时,优先用“事件序列 + 配置项 + SHOW BINLOG EVENTS/消费者偏移量”去定位。
一句话记住:先保证 binlog 与权限正确,再让 Maxwell 输出“可控、可重放”的 JSON;Kafka 侧用合适的分区与可靠性参数承接;最后再根据下游能力选择增量(Bireme)或一次性全量(mysql2pgsql)方案。
落地检查清单(最常踩坑)
- Kafka 里是否混入 DDL 或 bootstrap 事件(Bireme 是否能解析)
producer_partition_by是否导致分区倾斜(单库场景尤其常见)
kafka.acks与重试策略是否满足你的丢失容忍度
- Maxwell 用户是否具备读取所有目标表的权限(避免元数据缺表)